项目地址
介绍
可以将b站、youtube、快手、抖音、本地视频转换为markdown的文本(带视频截图),带有 ai改写 功能,可以自定义prompt。

修改
1. 删除cors校验
backend->app->main.py
allow_origins=origins,
修改为
allow_origins=["*"],
2. 前端修改端口号
BillNote_frontend->vite.config.ts
const apiBaseUrl = env.VITE_API_BASE_URL || 'http://localhost:8000'
修改为
const apiBaseUrl = 'http://localhost:8483'
2. 去掉图像理解
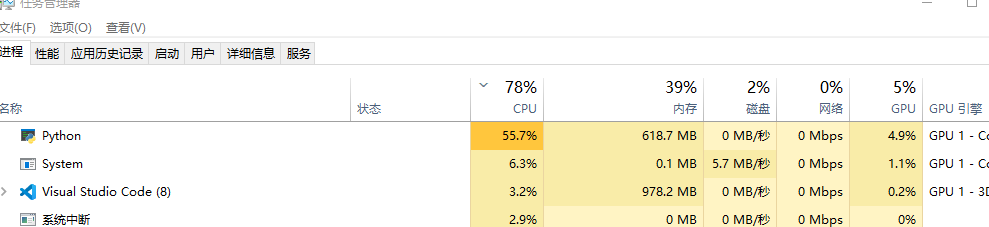
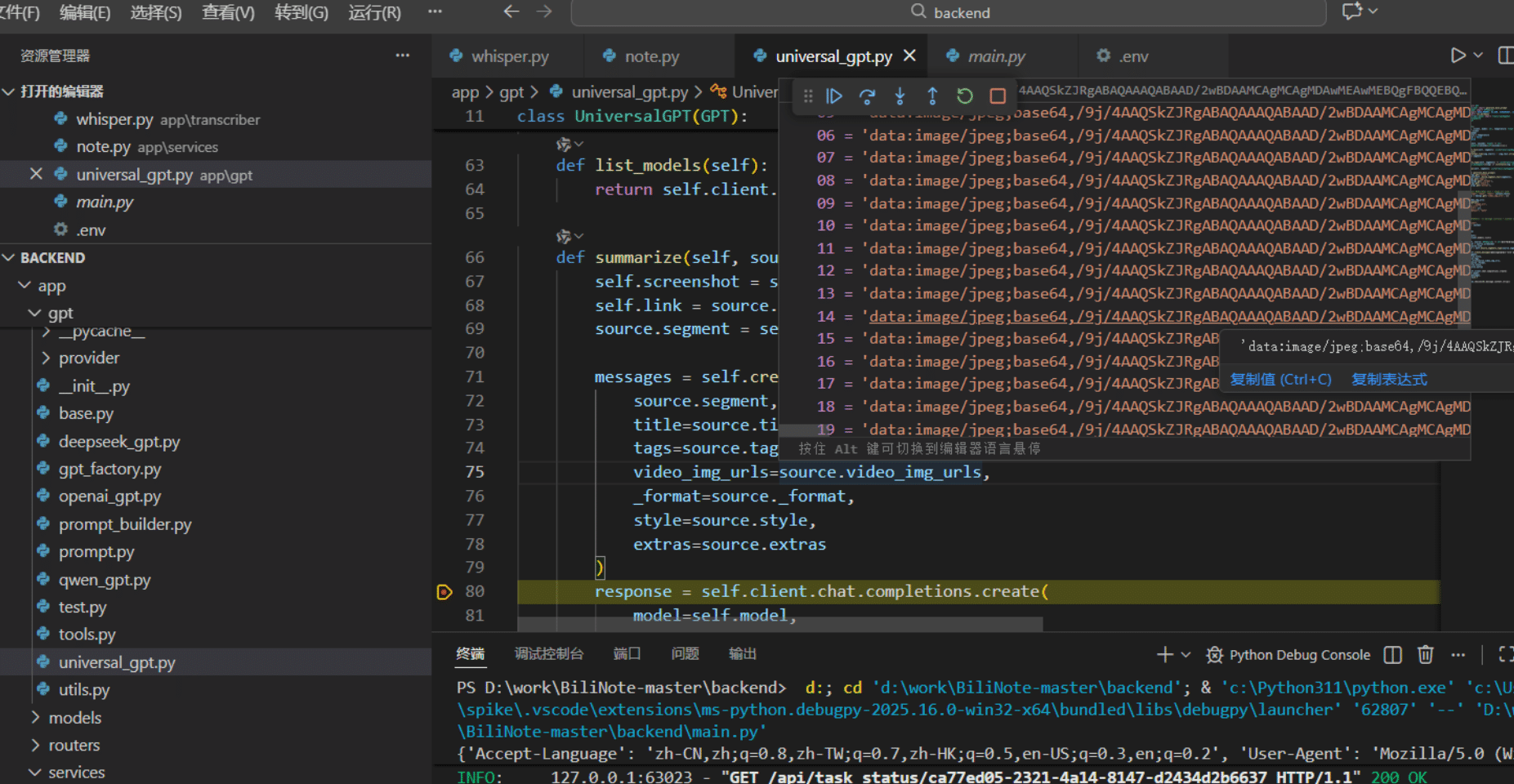
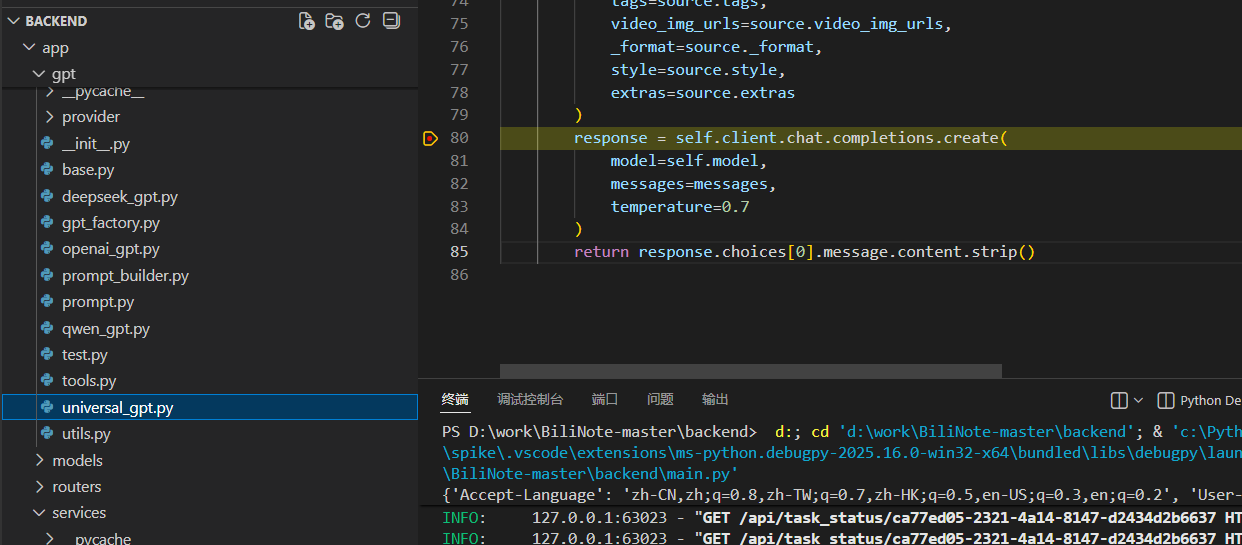
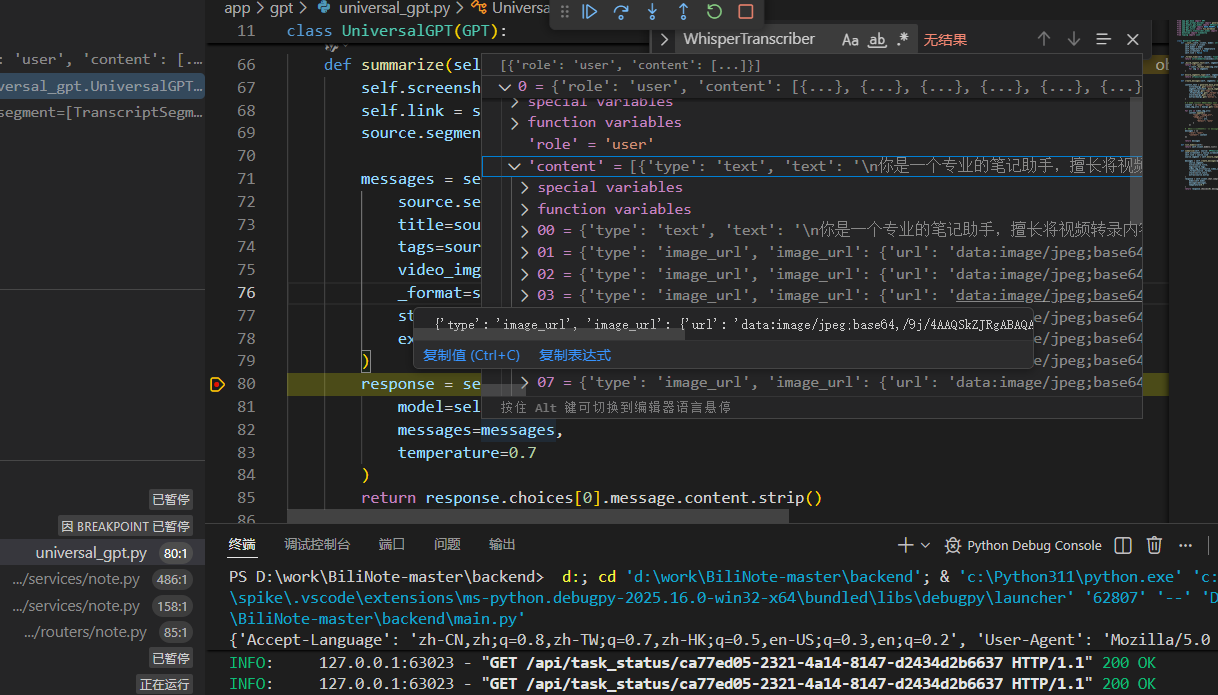
对我来说,我觉得这个视频理解是完全不必要的,因为每隔几秒截图给deepseek去理解会消耗大量的token(转成base64了),而且人工再次编辑的时候会删除很多图片,等于浪费了token,应该直接处理文本,然后再将图片插入ai处理后的文本中就可以了。所以让ai修改了一下它的python后端app->gpt->universal_gpt.py代码(也修复了乱码)。如下:
from app.gpt.base import GPT
from app.gpt.prompt_builder import generate_base_prompt
from app.models.gpt_model import GPTSource
from app.gpt.prompt import BASE_PROMPT, AI_SUM, SCREENSHOT, LINK
from app.gpt.utils import fix_markdown
from app.models.transcriber_model import TranscriptSegment
from datetime import timedelta
from typing import List
import re
class UniversalGPT(GPT):
def __init__(self, client, model: str, temperature: float = 0.7):
self.client = client
self.model = model
self.temperature = temperature
self.screenshot = False
self.link = False
def _format_time(self, seconds: float) -> str:
return str(timedelta(seconds=int(seconds)))[2:]
def _build_segment_text(self, segments: List[TranscriptSegment]) -> str:
return "\n".join(
f"{self._format_time(seg.start)} - {seg.text.strip()}"
for seg in segments
)
def ensure_segments_type(self, segments) -> List[TranscriptSegment]:
return [TranscriptSegment(**seg) if isinstance(seg, dict) else seg for seg in segments]
def create_messages(self, segments: List[TranscriptSegment], **kwargs):
"""
创建包含图片的消息(保留此方法供其他地方使用)
但在summarize方法中我们将使用纯文本版本
"""
content_text = generate_base_prompt(
title=kwargs.get('title'),
segment_text=self._build_segment_text(segments),
tags=kwargs.get('tags'),
_format=kwargs.get('_format'),
style=kwargs.get('style'),
extras=kwargs.get('extras'),
)
# 组装 content 数组,支持 text + image_url 混合
content = [{"type": "text", "text": content_text}]
video_img_urls = kwargs.get('video_img_urls', [])
for url in video_img_urls:
content.append({
"type": "image_url",
"image_url": {
"url": url,
"detail": "auto"
}
})
# 正确格式:整体包在一个 message 里,role + content array
messages = [{
"role": "user",
"content": content
}]
return messages
def _create_text_only_messages(self, segments: List[TranscriptSegment], **kwargs):
"""
创建纯文本消息,不包含图片
用于解决请求过大的问题
"""
content_text = generate_base_prompt(
title=kwargs.get('title'),
segment_text=self._build_segment_text(segments),
tags=kwargs.get('tags'),
_format=kwargs.get('_format'),
style=kwargs.get('style'),
extras=kwargs.get('extras'),
)
# 纯文本消息
messages = [{
"role": "user",
"content": content_text # 注意:这里是纯字符串,不是数组
}]
return messages
def _safe_fix_markdown(self, markdown_text: str) -> str:
"""
安全的Markdown修复函数,避免乱码
替换原有的fix_markdown函数
"""
if not markdown_text:
return markdown_text
# 移除可能的unicode转义序列(如果存在)
try:
import codecs
# 尝试解码,但如果已经正常则直接返回
if '\\u' in markdown_text or '\\x' in markdown_text:
# 有转义序列,尝试解码
try:
return codecs.decode(markdown_text, 'unicode_escape')
except:
# 解码失败,直接返回原文本
return markdown_text
else:
# 没有转义序列,直接返回
return markdown_text
except:
return markdown_text
def _clean_markdown_format(self, markdown_text: str) -> str:
"""
清理和优化Markdown格式
"""
if not markdown_text:
return markdown_text
# 修复常见的Markdown格式问题
cleaned = markdown_text
# 1. 修复标题格式(确保标题前有空行)
cleaned = re.sub(r'(\n)(#+ )', r'\1\2', cleaned)
# 2. 修复列表格式(确保列表项前有空行或正确缩进)
cleaned = re.sub(r'(\n)(\s*[-*+] )', r'\1\2', cleaned)
# 3. 修复代码块格式
cleaned = re.sub(r'```(.*?)```', r'\n```\1```\n', cleaned, flags=re.DOTALL)
# 4. 移除多余的空行(超过3个连续空行)
cleaned = re.sub(r'\n{4,}', '\n\n\n', cleaned)
# 5. 确保文本末尾有一个空行
cleaned = cleaned.rstrip() + '\n'
return cleaned
def _add_screenshots_to_markdown(self, markdown_text: str, screenshot_urls: List[str]) -> str:
"""
在Markdown文本末尾添加截图部分
使用纯Markdown格式,兼容性更好
"""
if not screenshot_urls:
return markdown_text
# 限制截图数量,避免过多
max_screenshots = 10
if len(screenshot_urls) > max_screenshots:
# 均匀采样选择关键截图
step = max(1, len(screenshot_urls) // max_screenshots)
selected_urls = []
for i in range(0, len(screenshot_urls), step):
if len(selected_urls) < max_screenshots:
selected_urls.append(screenshot_urls[i])
screenshot_info = f"(精选{len(selected_urls)}张,共{len(screenshot_urls)}张)"
else:
selected_urls = screenshot_urls
screenshot_info = f"(共{len(selected_urls)}张)"
# 添加截图部分 - 使用纯Markdown格式
screenshot_section = "\n\n---\n\n"
screenshot_section += "## 📸 视频截图\n\n"
screenshot_section += "以下为视频关键时间点的截图,可用于笔记配图:\n\n"
# 每行显示2张截图(使用表格格式)
screenshot_section += "| 截图 | 截图 |\n"
screenshot_section += "| :---: | :---: |\n"
for i in range(0, len(selected_urls), 2):
row = "|"
# 第一列
if i < len(selected_urls):
img_num = i + 1
row += f" <br>截图 {img_num} |"
else:
row += " |"
# 第二列
if i + 1 < len(selected_urls):
img_num = i + 2
row += f" <br>截图 {img_num} |"
else:
row += " |"
screenshot_section += row + "\n"
# 如果截图超过限制数量,显示提示
if len(screenshot_urls) > max_screenshots:
screenshot_section += f"\n*还有 {len(screenshot_urls) - max_screenshots} 张截图未显示*\n\n"
# 添加编辑提示
screenshot_section += "\n---\n\n"
screenshot_section += "> ** 编辑提示 **\n"
screenshot_section += "> - 截图仅作为参考,您可以根据需要删除不需要的截图\n"
screenshot_section += "> - 可以将截图调整到相关内容附近\n"
screenshot_section += "> - 可以添加图片说明文字\n"
screenshot_section += "> - 此部分为自动生成,可完全修改\n"
return markdown_text + screenshot_section
def summarize(self, source: GPTSource) -> str:
"""
总结文本内容(纯文本处理,解决413请求过大问题)
截图将在总结完成后作为Markdown图片链接插入到文本末尾
"""
self.screenshot = source.screenshot
self.link = source.link
source.segment = self.ensure_segments_type(source.segment)
# 使用纯文本消息,不包含图片,避免请求过大
messages = self._create_text_only_messages(
source.segment,
title=source.title,
tags=source.tags,
_format=source._format,
style=source.style,
extras=source.extras
)
# 调用API获取纯文本总结
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=self.temperature
)
# 获取纯文本总结结果
text_summary = response.choices[0].message.content.strip()
# 安全地修复Markdown格式(避免乱码)
text_summary = self._safe_fix_markdown(text_summary)
# 清理和优化Markdown格式
text_summary = self._clean_markdown_format(text_summary)
# 如果有截图,在总结文本后插入截图
if self.screenshot and hasattr(source, 'video_img_urls') and source.video_img_urls:
text_summary = self._add_screenshots_to_markdown(text_summary, source.video_img_urls)
return text_summary
def list_models(self):
return self.client.models.list()